xgboost原理
出处http://blog.csdn.net/a819825294
1.序
距离上一次编辑将近10个月,幸得爱可可老师(微博)推荐,访问量陡增。最近毕业论文与xgboost相关,于是重新写一下这篇文章。
关于xgboost的原理网络上的资源很少,大多数还停留在应用层面,本文通过学习陈天奇博士的PPT、论文、一些网络资源,希望对xgboost原理进行深入理解。(笔者在最后的参考文献中会给出地址)
地址。
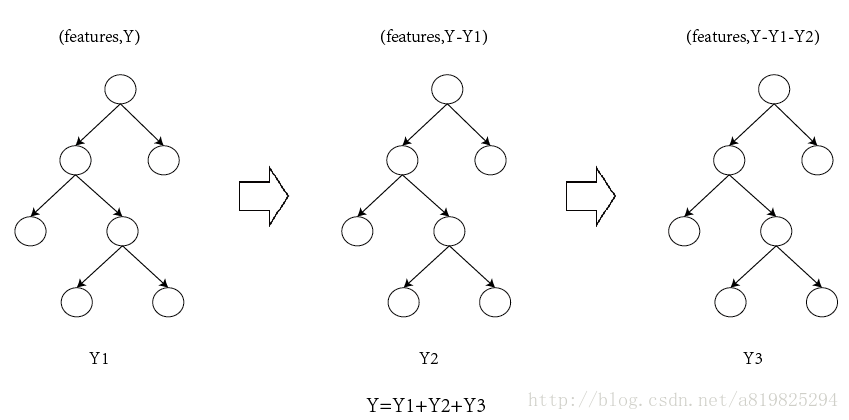
图1
如果不考虑工程实现、解决问题上的一些差异,xgboost与gbdt比较大的不同就是目标函数的定义。
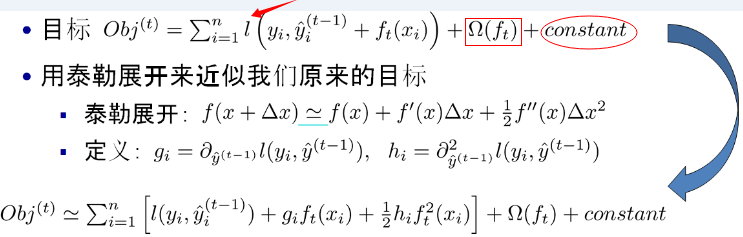
注:红色箭头指向的l即为损失函数;红色方框为正则项,包括L1、L2;红色圆圈为常数项。xgboost利用泰勒展开三项,做一个近似,我们可以很清晰地看到,最终的目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。
算法

(2)近似算法:
主要针对数据太大,不能直接进行计算

GridSearch
(2)Hyperopt
(3)老外写的一篇文章,操作性比较强,推荐学习一下。地址
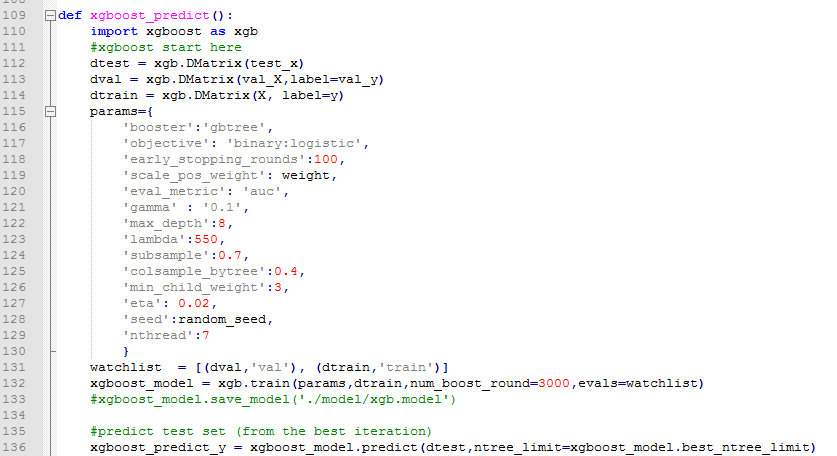
Python】
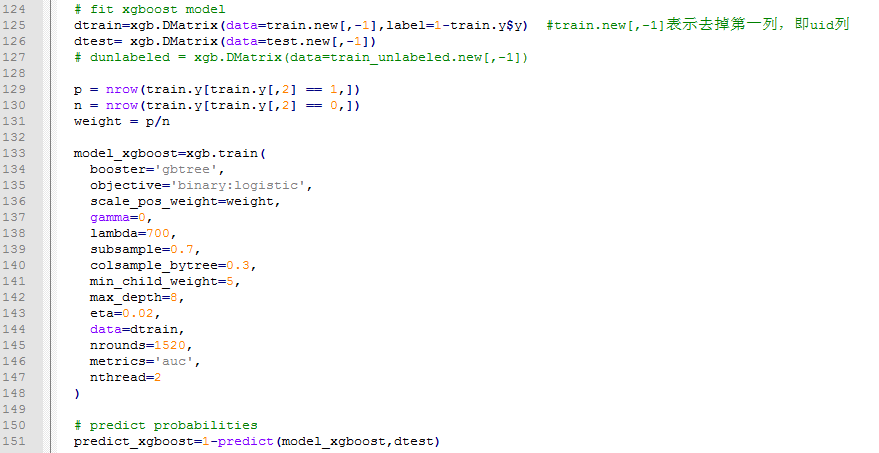
【R】
xgboost导读和实战
(2)xgboost
(3)自定义目标函数
(4)机器学习算法中GBDT和XGBOOST的区别有哪些?
(5)DART
(6)https://www.kaggle.com/anokas/sparse-xgboost-starter-2-26857/code/code
(7)XGBoost: Reliable Large-scale Tree Boosting System
(8)XGBoost: A Scalable Tree Boosting System