系统学习深度学习--GoogLeNetV1,V2,V3 【Incepetion V1-V3】
GoogLeNet Incepetion V1
这是GoogLeNet的最早版本,出现在2014年的《Going deeper with convolutions》。之所以名为“GoogLeNet”而非“GoogleNet”,文章说是为了向早期的LeNet致敬。
深度学习以及神经网络快速发展,人们不再只关注更给力的硬件、更大的数据集、更大的模型,而是更在意新的idea、新的算法以及模型的改进。
一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着巨量的参数。但是,巨量参数容易产生过拟合也会大大增加计算量。
文章认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。一方面现实生物神经系统的连接也是稀疏的,另一方面有文献1表明:对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。这点表明臃肿的稀疏网络可能被不失性能地简化。 虽然数学证明有着严格的条件限制,但Hebbian准则有力地支持了这一点:fire together,wire together。
早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。
所以,现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的。
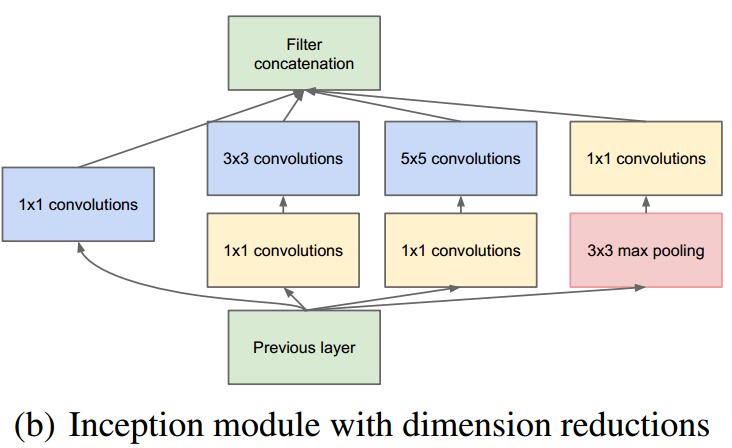
2,采用1x1卷积核来进行降维。
例如:上一层的输出为100x100x128,经过具有256个输出的5x5卷积层之后(stride=1,pad=2),输出数据为100x100x256。其中,卷积层的参数为128x5x5x256。假如上一层输出先经过具有32个输出的1x1卷积层,再经过具有256个输出的5x5卷积层,那么最终的输出数据仍为为100x100x256,但卷积参数量已经减少为128x1x1x32 + 32x5x5x256,大约减少了4倍。
具体改进后的Inception Module如下图:
测试的时候,这两个额外的softmax会被去掉。
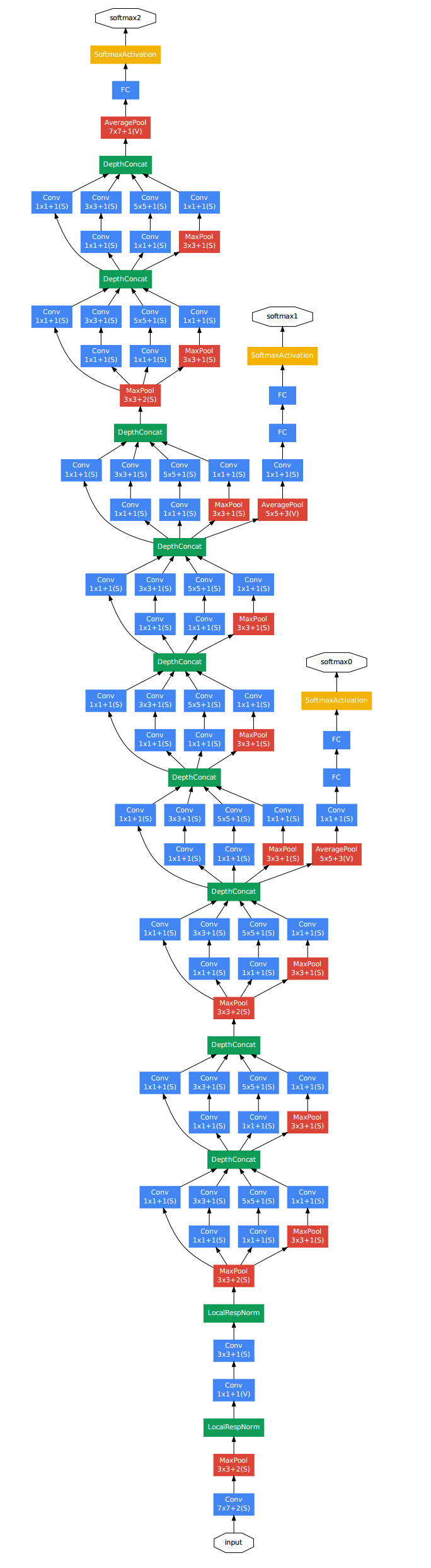
下图是一个比较清晰的结构图:
《Rethinking the Inception Architecture for Computer Vision》。
?
V4在后面先学习完ResNet后,再补充,因为作者是结合了ResNet后,提出的V4【[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261】