centos7-Logstash的使用
1.下载
Logstash官方下载
2.安装
2.1 yum安装
logstash.repo[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md安装
sudo yum install logstash
2.2 tar解压安装
下载安装包之后,解压即可3.配置
3.1 实例和管道
实例是指通过bin/logstash启用的一个服务 管道是指实例中处理数据的通道,包括三个部分收集器(input)、过滤器(filter)、转发器(output)。- 每一个运行的logstash实例至少有一个管道,数据的收集、过滤、转发都是在管道中进行的。
- 在一个实例中,每一个管道的收集器input有独立的一个线程进行处理,但是每个管道的过滤器filter、转发器output没有独立的线程,是所有管道共用的线程处理。
3.2 配置文件
配置是指logstash的配置文件,有两个配置文件logstash.yml和pipelines.yml,对应实例和管道的配置。- logstash.yml主要配置包括管道设置、主管道配置、api设置、模块设置、队列设置、死信队列设置、调试设置、插件设置、xpack设置等,是logstash运行实例的主要配置。
- pipelines.yml主要是每个logstash运行实例的多管道配置,默认管道是main,配置:
- pipeline.id: main
path.config: "/etc/logstash/conf.d/*.conf"- 如果指向的是一个具体的配置文件,则按该配置文件进行处理。
- 如果指向的是一个配置文件的目录,则会合并该目录下的所有文件,即形成一个大文件,如confd.d目录下有配置文件a.conf和b.conf
input {
file {
path => "/data/log/a.log"
}
}
filter {
date {
match => [ "message", "yyyy-MM-dd HH:mm:ss" ] locale => "Asia/Shanghai" timezone => "Europe/Paris" target => "messageDate"
}
}
output {
elasticsearch {
hosts => ["192.168.118.14"]
index => "a-log-%{+YYYY.MM.dd}"
}
}input {
file {
path => "/data/log/b.log"
}
}
filter {
extractnumbers {
source => "message" target => "message2"
}
}
output {
elasticsearch {
hosts => ["192.168.118.24"]
index => "a-log-%{+YYYY.MM.dd}"
}
}input {
# a.conf input
file {
path => "/data/log/a.log"
}
# b.conf input
file {
path => "/data/log/b.log"
}
}
filter {
# a.conf filter
date {
match => [ "message", "yyyy-MM-dd HH:mm:ss" ]
locale => "Asia/Shanghai" timezone => "Europe/Paris" target => "messageDate"
}
# b.conf filter
extractnumbers {
source => "message"
target => "message2"
}
}
output {
# a.conf output
elasticsearch {
hosts => ["192.168.118.14"]
index => "a-log-%{+YYYY.MM.dd}"
}
# b.conf output
elasticsearch {
hosts => ["192.168.118.24"] index => "a-log-%{+YYYY.MM.dd}"
}
}3.3 单实例单管道
单实例单管道,即启用一个实例,且实例只有一个管道。logstash安装后默认是单管道。 因为同一个实例中一个管道的配置文件目录如conf.d下的多个conf文件会被合并为一个配置文件,且实例的管道收集器线程分开,过滤器、转发器是线程共用,会导致过滤器、转发器多次执行,进而产生数据混乱。 这种情况下可以通过在收集器添加索引或者标签,在过滤器和转发器上通过条件判断进行区分,如下 a.confinput {
file {
path => "/data/log/a.log"
type => "a-log"
# tag => "a-log"
}
}
output {
# if "a-log" in [tags]
if [type] == "a-log" {
elasticsearch {
hosts => ["192.168.118.14"]
index => "a-log-%{+YYYY.MM.dd}"
}
}
}input {
file {
path => "/data/log/b.log"
type => "b-log"
# tag => "b-log"
}
}
output {
# if "b-log" in [tags]
if [type] == "b-log" {
elasticsearch {
hosts => ["192.168.118.24"]
index => "b-log-%{+YYYY.MM.dd}"
}
}
}3.4 单实例多管道
对于单实例单管道问题,可以通过为单实例配置多管道进行解决问题。多管道的配置参考:- pipeline.id: main # 管道名
path.config: "/etc/logstash/conf.d/*.conf" # 管道配置文件位置,将合并*.conf文件
pipeline.workers: 3 # cpu核数
pipeline.batch.size: 125 # 输入源批量事件的数量
queue.type: persisted # 队列类型,persisted硬盘模式
queue.page_capacity: 50mb # 硬盘模式每页数据大小
- pipeline.id: my-other-pipeline # 管道名
path.config: "/etc/different/path/p2.cfg" # 管道配置文件
pipeline.batch.size: 2 # 输入源批量事件的数量
pipeline.batch.delay: 1 # 轮询下一次事件的等待时长
queue.type: memory # 队列类型,memory内存模式3.5 多实例单管道
多实例单管道,即通过bin/logstash运行多个logstash实例。 注意:- 运行实例时logstash.yml配置文件中的path.data不同实例要配置不同的路径,不能共用一个数据存储的路径。
- 多实例相当于启用多个服务,占用更多的服务资源,所以非不得以情况下还是建议使用单实例多管道。
3.6 多实例多管道
多实例多管道,即启用多个实例,且每个实例都是多管道,参考前面。3.7 yum安装下配置
yum安装的logstash是以服务的形式运行,所以可以理解为logstash启动时是启动了一个logstash实例,当然也可以通过手动启动实例。 因此该模式适用也推荐使用单例单管道和单例多管道的配置。3.8 tar安装配置
tar安装的logstash是通过手动bin/logstash进行启动,可以启动多个实例,所以可以灵活使用单例单管道、单例多管道、多实例单管道、多实例多管道,综合考虑资源的情况去选择。4. nginx日志收集
现在采用单例单管道模式,以收集nginx日志为例,实操logstash服务。4.1 配置文件
logstash安装后main管道的默认配置文件是在/etc/logstash/conf.d/*.conf,因此我们拷贝/etc/logstash/logstash-sample.conf到/etc/logstash/conf.d/logstash-sample.conf,并改名为logstash-local-nginx-log.conf,并编辑,最终内容input {
# 从文件读取日志信息
file {
path => "/var/log/nginx/access.log"
type => "nginx-access-log"
# 从日志的第一行开始进行分析
# start_position => "beginning"
}
}
filter {
grok {
match => {
"message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:time}\] \"%{WORD:verb} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:http_status_code} %{NUMBER:bytes} \"(?\S+)\" %{QS:agent} \"(?\S+)\"\"(?\S+)\""
}
}
geoip {
source => "clientip"
}
}
output {
# 输出es
elasticsearch {
hosts => ["192.168.181.100:9200"]
index => "nginx-access-log-%{+YYYY.MM.dd}"
}
} 4.2 启用服务
# 查看服务状态
systemctl status kibana
# 启动服务
systemctl start kibana
# 停止服务
systemctl stop kibana
# 重启服务
systemctl restart kibana4.3 验证结果
打开elasticsearch_head,可以看到对应的索引,如下图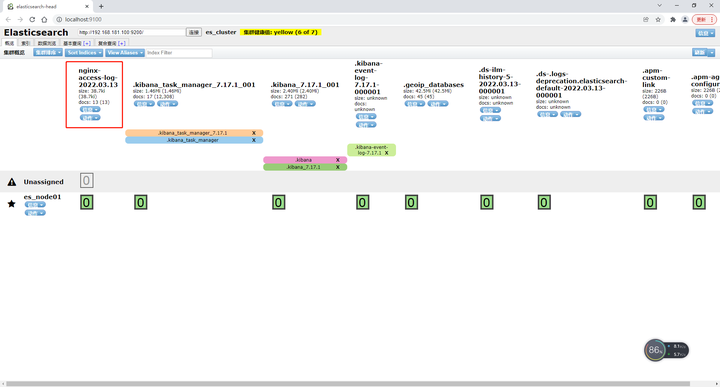 同样在kibana中stack manager的索引下,新建索引中可以找到对应的logstash转发的索引
同样在kibana中stack manager的索引下,新建索引中可以找到对应的logstash转发的索引
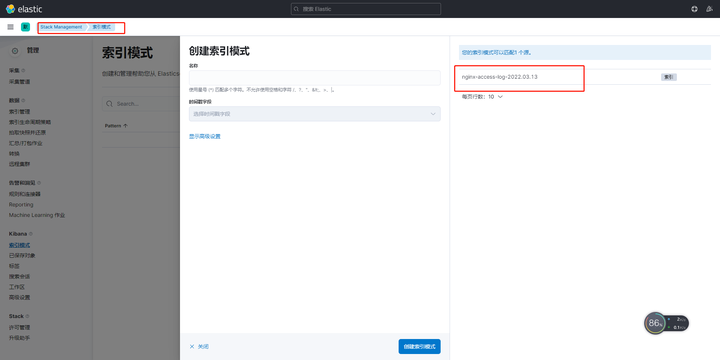 新建索引后
新建索引后
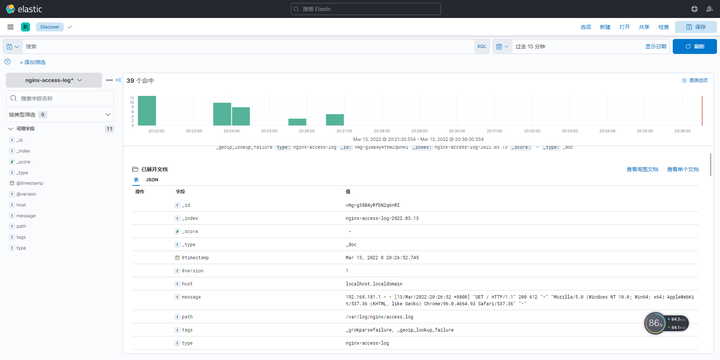
 在Analytics->Discover可以找到logstash转让的记录
在Analytics->Discover可以找到logstash转让的记录