Quartz定时任务调度
什么是Quartz
Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,完全由Java开发,可以用来执行定时任务,类似于java.util.Timer。但是相较于Timer, Quartz增加了很多功能。
Quartz就是一种任务调度计划。
- 它是由OpenSymphony提供的、开源的、java编写的强大任务调度框架
- 几乎可以集成到任何规模的运用程序中,如简单的控制台程序,复杂的大规模分布式电子商务系统
- 可用于创建简单的或复杂的计划任务
- 包含很多企业级功能,如支持JTA和集群等
Quartz应用场景
大部分公司都会用到定时任务这个功能。
拿火车票购票来说,当你下单后,后台就会插入一条待支付的task(job),一般是30分钟,超过30min后就会执行这个job,去判断你是否支付,未支付就会取消此次订单;当你支付完成之后,后台拿到支付回调后就会再插入一条待消费的task(job),Job触发日期为火车票上的出发日期,超过这个时间就会执行这个job,判断是否使用等。
在我们实际的项目中,当Job过多的时候,肯定不能人工去操作,这时候就需要一个任务调度框架,帮我们自动去执行这些程序。那么该如何实现这个功能呢?
(1)首先我们需要定义实现一个定时功能的接口,我们可以称之为Task(或Job),如定时发送邮件的task(Job),重启机器的task(Job),优惠券到期发送短信提醒的task(Job),实现接口如下:
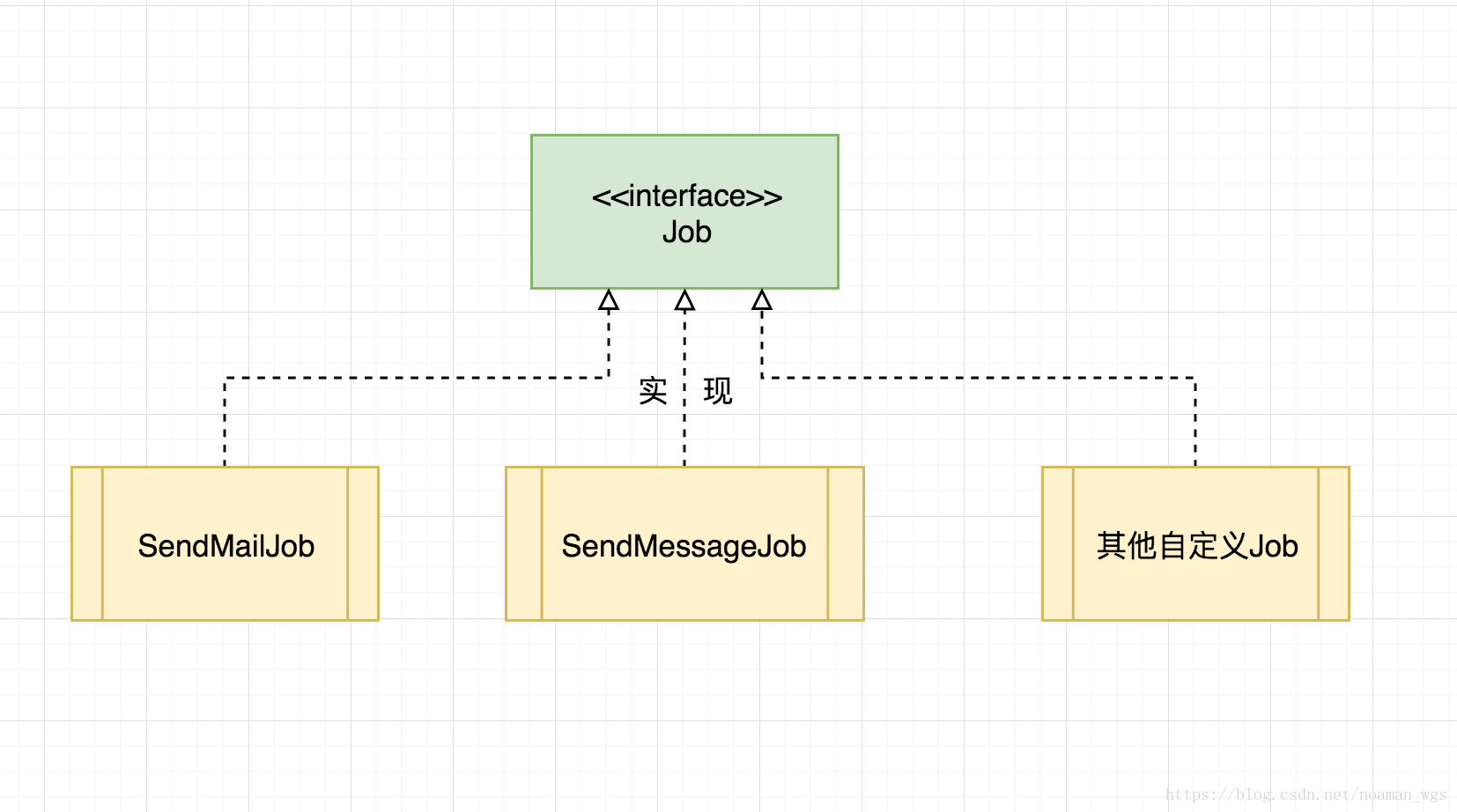
(2)有了任务之后,还需要一个能够实现触发任务去执行的触发器,触发器Trigger最基本的功能是指定Job的执行时间,执行间隔,运行次数等。
(3)有了Job和Trigger后,怎么样将两者结合起来呢?即怎样指定Trigger去执行指定的Job呢?这时需要一个Schedule,来负责这个功能的实现。
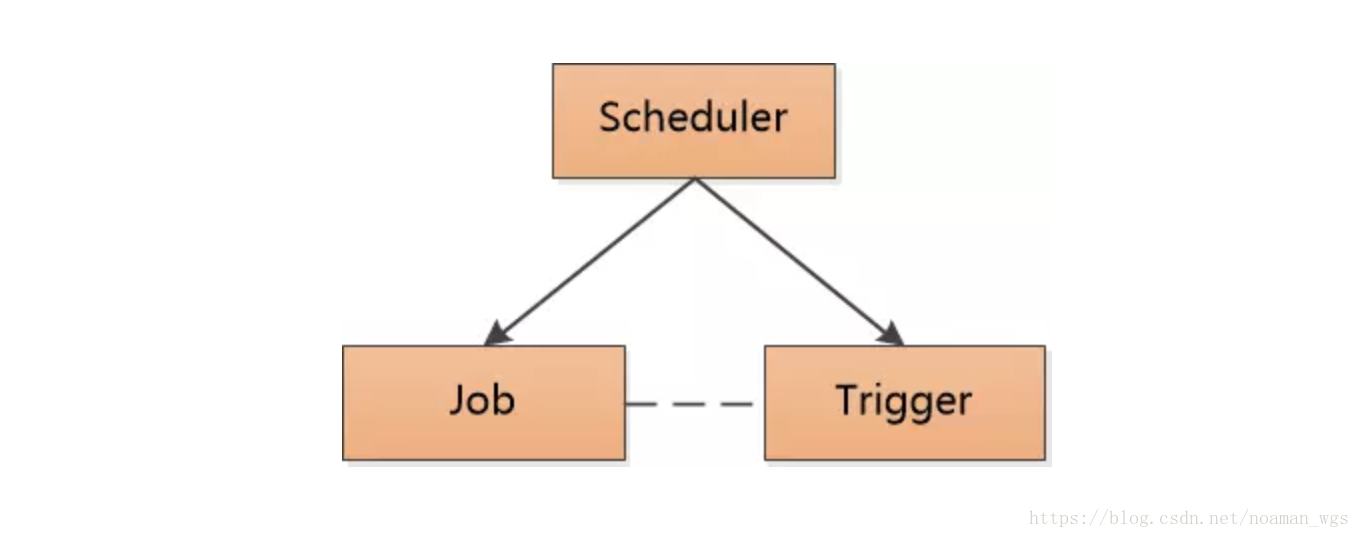
上面三个部分就是Quartz的基本组成部分:
- 调度器:Scheduler
- 任务:JobDetail
- 触发器:Trigger,包括SimpleTrigger和CronTrigger
Quartz原理
当要深入研究一个技术时,研究它的体系结构和内部运行原理,不失为一种较好的方式。同理,我们在研究Quartz时,也采用类似的方法,
下图为Quartz的大致结构图。
Quartz的模块
Quartz几个关键概念
Job
负责定义任务所处理的逻辑,实现类需要实现org.quartz.Job接口,是Quartz中的一个接口,接口下只有execute方法,在这个方法中编写业务逻辑。
public interface Job { void execute(JobExecutionContext context) throws JobExecutionException; }
JobDetail
JobDetail,顾名思义,就是表示关于每个Job的相关信息,它主要包括两个核心组件,即Job Task和JobData Map。
JobDetail用来绑定Job,为Job实例提供许多属性:
- name
- group
- jobClass
- jobDataMap
JobDetail绑定指定的Job,每次Scheduler调度执行一个Job的时候,首先会拿到对应的Job,然后创建该Job实例,再去执行Job中的execute()的内容,任务执行结束后,关联的Job对象实例会被释放,且会被JVM GC清除。
JobDetail定义的是任务数据,而真正的执行逻辑是在Job中。
为什么设计成JobDetail + Job,不直接使用Job
JobDetail定义的是任务数据,而真正的执行逻辑是在Job中。
这是因为任务是有可能并发执行,如果Scheduler直接使用Job,就会存在对同一个Job实例并发访问的问题。而JobDetail & Job 方式,Sheduler每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题。
Trigger
Trigger,表示触发器,根据配置规则来触发执行计划调度job,它主要包括两个核心组件,即SimpleTrigger和CronTrigger。其他Tigger基本都可以通过这两种实现。Trigger还可以定义错过的任务如何处理。
SimpleTrigger
SimpleTrigger可以实现在一个指定时间段内执行一次作业任务或一个时间段内多次执行作业任务。
下面的程序就实现了程序运行5s后开始执行Job,执行Job 5s后结束执行:
Date startDate = new Date(); startDate.setTime(startDate.getTime() + 5000); Date endDate = new Date(); endDate.setTime(startDate.getTime() + 5000); Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "triggerGroup1") .usingJobData("trigger1", "这是jobDetail1的trigger") .startNow()//立即生效 .startAt(startDate) .endAt(endDate) .withSchedule(SimpleScheduleBuilder.simpleSchedule() .withIntervalInSeconds(1)//每隔1s执行一次 .repeatForever()).build();//一直执行
CronTrigger
CronTrigger功能非常强大,是基于日历的作业调度,而SimpleTrigger是精准指定间隔,所以相比SimpleTrigger,CroTrigger更加常用。CroTrigger是基于Cron表达式的,先了解下Cron表达式:
由7个子表达式组成字符串的。
下面的代码就实现了每周一到周五上午10:30执行定时任务:
/** * Created by wanggenshen * Date: on 2018/7/7 20:06. * Description: XXX */ public class MyScheduler2 { public static void main(String[] args) throws SchedulerException, InterruptedException { // 1、创建调度器Scheduler SchedulerFactory schedulerFactory = new StdSchedulerFactory(); Scheduler scheduler = schedulerFactory.getScheduler(); // 2、创建JobDetail实例,并与PrintWordsJob类绑定(Job执行内容) JobDetail jobDetail = JobBuilder.newJob(PrintWordsJob.class) .usingJobData("jobDetail1", "这个Job用来测试的") .withIdentity("job1", "group1").build(); // 3、构建Trigger实例,每隔1s执行一次 Date startDate = new Date(); startDate.setTime(startDate.getTime() + 5000); Date endDate = new Date(); endDate.setTime(startDate.getTime() + 5000); CronTrigger cronTrigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "triggerGroup1") .usingJobData("trigger1", "这是jobDetail1的trigger") .startNow()//立即生效 .startAt(startDate) .endAt(endDate) .withSchedule(CronScheduleBuilder.cronSchedule("* 30 10 ? * 1/5 2018")) .build(); //4、执行 scheduler.scheduleJob(jobDetail, cronTrigger); System.out.println("--------scheduler start ! ------------"); scheduler.start(); System.out.println("--------scheduler shutdown ! ------------"); } }
JobExecutionContext
JobExecutionContext中包含了Quartz运行时的环境以及Job本身的详细数据信息。
当Schedule调度执行一个Job的时候,就会将JobExecutionContext传递给该Job的execute()中,Job就可以通过JobExecutionContext对象获取信息。
主要信息有:
JobDataMap
JobDataMap实现了JDK的Map接口,可以以Key-Value的形式存储数据。
JobDetail、Trigger都可以使用JobDataMap来设置一些参数或信息,
Job执行execute()方法的时候,JobExecutionContext可以获取到JobExecutionContext中的信息:
JobDetail jobDetail = JobBuilder.newJob(PrintWordsJob.class)
.usingJobData("jobDetail1", "这个Job用来测试的") .withIdentity("job1", "group1").build(); Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger1", "triggerGroup1") .usingJobData("trigger1", "这是jobDetail1的trigger") .startNow()//立即生效 .withSchedule(SimpleScheduleBuilder.simpleSchedule() .withIntervalInSeconds(1)//每隔1s执行一次 .repeatForever()).build();//一直执行
Job执行的时候,可以获取到这些参数信息:
@Override public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException { System.out.println(jobExecutionContext.getJobDetail().getJobDataMap().get("jobDetail1")); System.out.println(jobExecutionContext.getTrigger().getJobDataMap().get("trigger1")); String printTime = new SimpleDateFormat("yy-MM-dd HH-mm-ss").format(new Date()); System.out.println("PrintWordsJob start at:" + printTime + ", prints: Hello Job-" + new Random().nextInt(100)); }
JobStore
JobStore,表述任务存储器,主要存储job和trigger相关信息。
SchedulerFactory
SchedulerFactory负责初始化,读取配置文件,然后创建Scheduler。
Scheduler
Scheduler,表述任务计划,中枢调度器,负责管理Trigger/JobDetail和3个调度线程,具体job和job相关trigger就能够被注入其中,从而实现任务计划调度。其主要常用的方法:
- Start --启动执行计划
- Shutdowm --关闭执行计划
QuartzSchedulerThread
主调度线程
MisfireHandler
错失触发的任务恢复线程,。更新Trigger的触发时间。
ClusterManager
集群协调线程。定期心跳,自动recover。同主程序中的recover。
示例一
引入Maven依赖
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-quartzartifactId> dependency>
编写具体的job
public class TestJob extends QuartzJobBean { @Override protected void executeInternal(JobExecutionContext context) throws JobExecutionException { System.out.println("Test job executed."); } }
定义JobDetail, 把Job的class类型传入。Spring自动处理
@Bean public JobDetail testJob(){ return JobBuilder .newJob(TestJob.class) .withIdentity("TestJob") .storeDurably() .requestRecovery() .build(); }
定义Trigger, 通过Key关联JobDetail。Spring 自动处理。
@Bean public Trigger testTrigger(){ return TriggerBuilder.newTrigger() .withIdentity("TestTrigger") .forJob("TestJob") .withSchedule(CronScheduleBuilder .cronSchedule("0/6 * * * * ? ") .withMisfireHandlingInstructionDoNothing()) .build(); }
如果需要不同的数据库,定义一个@Primary主库,和一个@QuartzDataSource quartz专用库
@Bean @Primary @ConfigurationProperties(prefix="spring.datasource") public DataSource primaryDataSource() { return DataSourceBuilder.create().build(); } @Bean @QuartzDataSource @ConfigurationProperties(prefix="spring.datasource.quartz") public DataSource quartzDataSource() { return DataSourceBuilder.create().build(); }
application.properties 都有默认配置,第一行启用数据库,后面两行是cluster功能
spring.quartz.job-store-type=jdbc spring.quartz.org.quartz.scheduler.instanceId = AUTO spring.quartz.org.quartz.jobStore.isClustered = true
虽然Spring提供了自动建库的功能,但是第一次建完之后需要改成never
spring.quartz.jdbc.initializeSchema=ALWAYS
#spring.quartz.jdbc.initializeSchema=NEVER
参考:
(1)https://www.cnblogs.com/wangjiming/p/10027439.html
(2)https://blog.csdn.net/noaman_wgs/article/details/80984873
(3)https://www.jianshu.com/p/bac0e919f3ee