时间规划在Optaplanner上的实现
 针对不同的时间规划要求,Optaplanner提供了3常用的规划模式,分别是时间槽模式- Time Slot Pattern,时间粒模式 - Time Grain Pattern, 和时间链模式 - Chained Through Time Pattern.下面分别对这三种模式的特征,适用场景和使用方法进行详细介绍。因为翻译准确度原因(对自己的英文水平缺乏自信:P), 下文介绍中均直接使用Time Slot, Time Grain 和 Chained Through Time.以避免本文件的翻译不当造成误解。
针对不同的时间规划要求,Optaplanner提供了3常用的规划模式,分别是时间槽模式- Time Slot Pattern,时间粒模式 - Time Grain Pattern, 和时间链模式 - Chained Through Time Pattern.下面分别对这三种模式的特征,适用场景和使用方法进行详细介绍。因为翻译准确度原因(对自己的英文水平缺乏自信:P), 下文介绍中均直接使用Time Slot, Time Grain 和 Chained Through Time.以避免本文件的翻译不当造成误解。
时间槽模式 - Time slot
Time Slot在应用时有一些适用条件,满足以下所有条件,才适用:- 规划实体中的规划变量是一个时间区间;
- 一个规划变量的取值最多仅可分配一个时间区间;
- 规划变量对应的时间区间是等长的。
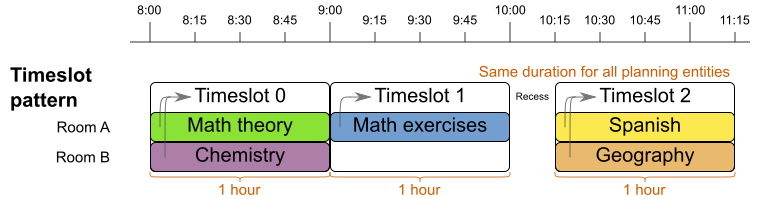
从图中可以看出,每门课所需的时间都是固定一小时。具体到这个模式的应用,因为其原理、结构和实现起来都相当简单,本文不通过示例详细讲解了。可参考示例包中的Course timetabling中的设计和代码。
时间粒模式 - Time Grain
在相当多运筹优化场景中,需要规划的时间长短是不固定的,不同的任务其所需的时间有长短之分。这种需求下,若使用Time slot模式就无法实现时间上的精确规划。那些就要使用更灵活,时间粒度更小的Time Grain模式。从Time Grain模式的名称中的Grain可以推测到,此模式是将时间细分成一个一个颗粒并应用于规划。例如可以设定为每1分钟,5分钟,30分钟,1小时等固定的长度,为一个Grain的长度。 Time Grain模式适用条件:- 规划变量是时间区间;
- 业务上对应于规划变量的时间区间可以不等长,但必须是Grain的倍数。
从上图可以看到,每个会议所需的时间长度是不相等的,但是其长度必然是一个Time Grain的倍数,从图中上方的时间刻度可以比划出一个TimeGrain应该是15分钟。例如Sales meeting占用了4个Time Grain,即时长1小时。Time Grain模式的使用会相对Time Slot更灵活,适用范围会更广。通过设置可知,其实适用于Time Slot模型的情形,是完全可以通过TimeGrain模式实现的,只是实现起来会更复杂一些。那么Time Grain模式的设计要点在哪里呢?要了解其设计原理,就得先掌握Time Grain的结构及其对时间的提供方法。
Time Grain中的重点在于一个Grain的设计,与Time Slot中的slot一样,Time Grain中的Grain表示的也是一个时间区间,只不过它所表达的意义不仅在于一个Time Grain的时间区间内,每个Grain的序号也是关键因素,当一个Grain被分配到一个规划变量时,Grain的序号决定了它与时间轴的映射位置。在生产计划中,若一个Grain被分配到一个任务时,表示任务起止于这个Grain的开始时刻。 即该任务的开始时间是哪个Grain内对应的时间区间内,那么这个Grain的开始时间,就是这个任务的开始时间;通过这个任务的长度,推算出它需要占用多少个Grain, 进而推算出它的结束时间会在哪个Grain内,那么这个Grain的结束时间,即是这个任务的结束时间。 还是以上图为例,其中的Sales meeting,它的起始是在grain0内,grain0的起始时间是8:00,那么这个会议的起始时间就是8:00。这个会议的长度是1小时,所以它占用了4个Grain,因此,第4个Grain的结束时间就是会议的结束时间,也就是图中Grain3的结束时间 - 9:00,是这个会议的结束时间。进一步分析也知,若这个会议时长是1:10, 那么它的结束时间将会落于gran4内(第5个grain), 那么它的结束时间就是grain4的结束时间 - 9:15. 因此,总结起来,我们在实现这个模式的时候有以下要点在设计时需要注意:- 设计好每个Grain的粒度,也就是时间长度。并不是粒度越细越好,例如以1秒钟作为一个粒度,是不是就可以将任务的时间精度控制在1级呢?理论上是可以的,但日常使用中不太可行。因为这样的设计会产生过量的Grain,Grain就是Value Range,当可选值的数量过多时,整个规划问题的规模就会增大,其时间复杂度就会指数级上升,从而令优化效果降低。
- 定义好每个Grain与绝对时间的映射关系。这个模式中的Time Grain其时间上是相对的。如何理解呢?就是说,这个模式在运行的时候,会把初始化出来的Grain对象列表,以Index(Grain的序号)为序形成一个连接的时间粒的序列。列表中每一个具体的Grain对应的绝对时间是什么时候呢?是以第一个Grain作为参照推算出来的。例如上图中的第一个Grain - grain0它的起始时间是8:00, 那么第6个grain - grain5的起始时间就是9:30,这个时间是通过grain0加上6个grain的时长推算出来的,也就是8:00加上1.5小时,因此得到的是9:30。因此,当你设定Time Grain与绝对时间的对应关系时,就需要从业务上考虑,grain0的起始是什么时刻;它决定了后续所有任务的时间。
public int calculateOverlap(MeetingAssignment other) { if (startingTimeGrain == null || other.getStartingTimeGrain() == null) { return 0; }上述代码是判断两个会议的TIme Grain, 若存在重叠,则返回重叠量,供引擎的评分机制来判断各个solution的优劣。
int start = startingTimeGrain.getGrainIndex(); int end = start + meeting.getDurationInGrains(); int otherStart = other.startingTimeGrain.getGrainIndex(); int otherEnd = otherStart + other.meeting.getDurationInGrains(); if (end < otherStart) { return 0; } else if (otherEnd < start) { return 0; } return Math.min(end, otherEnd) - Math.max(start, otherStart); }
时间链模式 - Chained Through Time
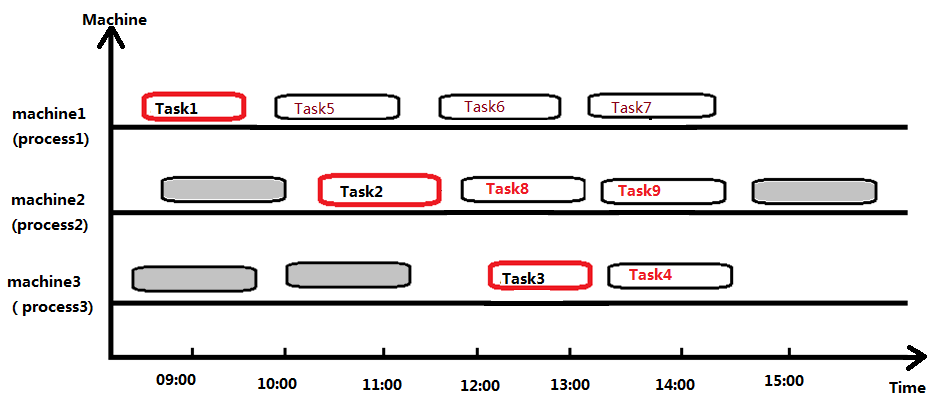
前面提出的两种时间模式,其实有较多的相似之处,都是将时间段划分为单个个体,再将这些个体作为规划变量的取值范围,从而实现与空间规划一致的规划模式。但更复杂的场景下,将时间转化为“空间”的做法,未必能行得通。例如带时间窗口的路径规划,多工序多资源生产计划等问题,其时间维度是难以通过Time Slot或Time Grain模式实现的。我增尝试将Time Grain模式应用于多工序多资源条件下的生产计划规划;其原理上是可行的,但仍然会到到一些相当难解决的问题。其中之一就是Time Grain的粒度大小问题,若需要实现精确到分钟的计划,当编排一个时间跨度较大的计划时,就会引起问题规模过大的问题,从而论引擎效率骤降。另外就是实现相邻任务的重叠和先后次序判断时,会遇到一些难以解决的,问题需要花费较多的精力去处理。因此,Optaplanner引入了第三种时间规划模式 - 时间链模式(同样是翻译问题,下称Chained Through Time模式)。 Chained Through Time模式顾名思义就是应用了链状结构的特性,来实现时间的规划。它的设计思想是,规划变量并不是普通的时间或空间上的值, 而是另外一个规划实体;从而形成一个由各个首尾相接的规划实体链,即Value Range的范围就是规划实集合本身。通过规划实体间的链状关系,来推算各个实体的起止时间。事实上,Optaplanner中将规划实体环环相扣形成链的特性,其主要目的并非为了实现时间规划,而是为了解类似TSP,VRP等问题而提供的。这些问题需要规划的,是各个节点之间形成的连通关系;在约定规则下,求解最佳连通方案。根据不同的场景要求,所求的目标有“最短路径”,“最小重复节点”,“最在连接效率”等。在时间规划的功能方面,其实现方式与上两种模式类似。以生产计划的例子来说,通过Chained Through Time模式获得各任务的连接关系与次序后,就可以根据链中首个任务的开始时间,结合各任务的持续时间,推算出各个任务精确的起止时间了,甚至可以精确到秒。所以此模式用于时间规划,只是它的一个“副业”,引擎使用Chained Through Time模式时,并不是直接对时间进行规划优化,而是在优化规划实体之间的连接关系;时间作为这个规划实体中的一个影子变量(Shadow variable)进行计算,最终通过评分机制对这个影子变量进行约束限制,从而得到时间优化的方案。与Time Slot和Time Grain相比,Chained Through Time最大的特性是通过次序来推导时间,而另外两种模式则是需要通过时间来反映任务之间的先后关系。 虽然Chained Through Time模式的作用相当巨大且广泛,但该模式的设计与实现难度又是三个模式中最高的,实现起来相对复杂。下面来进一步对其进行深入讨论。Chained Through Time模式的意义
Chained Through Time模式通过对正在进行规划的所有规划实体建立链状关系,来实现时间推导,其推导结果示意图如下。从图中可以看到,分配给Ann有两个任务(FR taxes和SP taxes),其中第一个任务FR taxes的开始时刻是固定为本次计划的最早时间,而第二个任务SP taxes的开始时刻,则是根据第一个任务推导出来的 - 等于第一个任务的开始时刻加上其持续时间。因此,需要在约束的限制下,引擎过过各种约束分数的判断,生成一个相对最合理的实体连接方案,再在这个方案的基础上来推导时间,或将时间纳入作为约束条件,实现对连接方案的影响,从而实现了时间维度的规划优化。Chained Through Time的内存模型
规划实体形成的链是由引擎自动生成的,每生成的一个方案都是由各规划实体之间的相对位置变化而成的。在创建的这些规划实体构成的链中,它会遵循以下原则:- 一条链由一个Anchor(锚),和零或,或1个,或多个Entity(实体,其实就是规划实体)构成;
- 一条链必须有且仅有一个Anchor(锚);
- 一条链中的Entity或Anchor之间是一对一的关系,不可出现合流或分流结构;
- 一条链中的Entity或Anchor不可出现循环。
Chained Through Time模式的设计实现
通过上面的链结构,我们了解到,一条链中将会存在两种对象,一种是Anchor, 一种是Entity.对么它们分别代表现实场景中的什么业务实体呢?其实Entity是其常容易理解,如果是生产计划案例中,它代表的是每个任务;在车辆路线规划案例中,它代表的是每个车辆需要途径的派件/揽件客户。而Anchor则表未任务所在的机台,及各个投/揽方案中的每一车辆。因此,这两种不同的对象,在内容中会形成依赖关系,即一个Entity的前一步可以是另外一个Entiy, 也可以是一个Anchor。以生产计划的业务场景来描述,则表示一个任务的前一个任务,可以是另外一个任务(Entity),也可以是一个机台(Anchor,当这个任务是这个机台的首个任务时)。因此,在我们设计它的时候需要把这两种不同的业务实体抽象为同一类才有办法实现它们之间的依赖,事实上这种抽象关系,在面向对象的原则,在业务意义上来说,是不成立的,仅仅是为了满足它们形成同一链的要求才作出的计划。如下是一个任务与机台的类设计图。可以看到,我从Taskg与Machine抽象了一个父类Step(这是我想到的最合适类名了),那么每一个任务的前一个Step有可能是另外一个任务,也有可能是一个机台。时间推算方法
Chained Through Time模式与其两种时间规划模式不同,本质上它并不对时间进行规划,只对实体之间的关系进行规划优化。因此,在引擎每一个原子操作中需要通过对VariableListener接口的实现,来对时间进行推算,并在完成推算后,由引擎通过评分机制进行约束评分。一个Move有可能对应多个原子操作,一个Move的操作种类,可以参见开发 手册中关于Move Selector一章,在以后对引擎行为进行深入分析的文章中,我将会写一篇关于Move Seletor的文件,来揭示引擎的运行原理。在需要进行时间推算时,可以通过实现接口的afterVariableChanged方法,对当前所处理的规划实体的时间进行更新。因为Chained Through Timea模式下,所有已初始化的规划实体都处在一条链上;因此,当一个规划实体的时间被更新后,跟随着它的后一个规划实体的时间也需要被更新,如此类推,直到链上最后一个实体,或出现一个时间正好不需要更新的规划实体,即该规划实体前面的所有实体的时间出现更新后,其时间不用变化,那么链上从它往后的规划实体的时候也无需更新。
以下是VariableListener接口的afterVariableChanged及其处理方法。
// 实现VariableListener的类 public class StartTimeUpdatingVariableListener implements VariableListener{ // 实现afterVariableChanged方法 @Override public void afterVariableChanged(ScoreDirector scoreDirector, Task task) { updateStartTime(scoreDirector, task); } @Override public void beforeEntityAdded(ScoreDirector scoreDirector, Task task) { // Do nothing } @Override public void afterEntityAdded(ScoreDirector scoreDirector, Task task) { updateStartTime(scoreDirector, task); } . . . }
//当一个任务的时候被更新时,顺着链将它后面所有任务的时候都更新 protected void updateStartTime(ScoreDirector scoreDirector, Task sourceTask) { Step previous = sourceTask.getPreviousStep(); Task shadowTask = sourceTask; Integer previousEndTime = (previous == null ? null : previous.getEndTime()); Integer startTime = calculateStartTime(shadowTask, previousEndTime); while (shadowTask != null && !Objects.equals(shadowTask.getStartTime(), startTime)) { scoreDirector.beforeVariableChanged(shadowTask, "startTime"); shadowTask.setStartTime(startTime); scoreDirector.afterVariableChanged(shadowTask, "startTime"); previousEndTime = shadowTask.getEndTime(); shadowTask = shadowTask.getNextTask(); startTime = calculateStartTime(shadowTask, previousEndTime); } }
规划实体的设计
上一步我们介绍了如何通过链在引擎的运行过程中进行时间推算,那么如何设定才能让引擎可以执行VariableListener中的方法呢,这就需要在规划实体的设计过程中,反映出Chained Through Time的特性了。我们以上面的类图为例,理解下面其设计要求,在此示例中,把Task作为规划实体(Planning Entity), 那么在Task类中需要定义一个Planning Variable(genuine planning variable), 它的类型是Step,它表示当前Task的上一个步骤(可能是另一个Task,也可能是一Machine). 此外,在 @PlanningVariable注解中,添加graphType = PlanningVariableGraphType.CHAINED说明。如下代码:
// Planning variables: changes during planning, between score calculations. @PlanningVariable(valueRangeProviderRefs = {"machineRange", "taskRange"}, graphType = PlanningVariableGraphType.CHAINED) private Step previousStep;
以上代码说明,规划实体(Task)的genuine planning variable名为previousStep, 它的Value Range有两个来源,分别是机台列表(machineRange)和任务列表(taskRange),并且添加了属性grapType=planningVariableGraphType.CHAINED, 表明将应用Chained Through Time模式运行。
有了genuine planning variable, 还需要Shadow variable, 所谓的Shadow variable,在Chained Through Time模式下有两种作用,分别是:
1. 用于建立两个对象(Entity或Anchor)之间的双向依赖关系;即示例中的Machine与Task, 相邻的两个Task。
2. 用于指定当genuine planning variable的值在规划运算过程产生变化时,需要更改哪个变量;即上面提到的开始时间。
,对于第一个作用,其代码体现如下,在规划实体(Task)中,以@AnchorShadowVariable注解,并在该注解的sourceVariableName中指定该Shadow Variable在链上的前一个对象指向的是哪个变量。
// Shadow variables // Task nextTask inherited from superclass @AnchorShadowVariable(sourceVariableName = "previousStep") private Machine machine;
上述代码说明成员machine是一个Anchor Shadow Variable, 在链上,它连接的前一个实体是实体类的一个成员 - previousStep.
Chained Through Time中的链需要形成双向关系(bi-directional),下图是路线规划示例中。一个客户与上一个停靠点之间的双向关系。
在规划实体(Task)中我们已经定义了前一个Step,并以@AnchorShadowVariable注解标识。而双向关系中的另一方,则需要在相邻节点中的前一个节点定义。通过链的内存模型,我们可以知道,在生产计划示例中,一个实体的前一个节点的类型可能是另一个Task, 也要能是一个Machine, 因此,前一个节点指向后一个节点的规划变量,只能在Task与Machine的共同父类中定义,也就是需要在Step中实现。因此,在Step类中需要定义另一个Shadow Variable, 因为相对于Task中的Anchor Shadow variable, 它是反现的,因此,它需要通过@InverseRelationShadowVariable注解,说明它在链上起到反向连接作用,即它是指向后一个节点的。代码如下:
@PlanningEntity public abstract class Step{ // Shadow variables @InverseRelationShadowVariable(sourceVariableName = "previousStep") protected Task nextTask; . . . }
可以从代码中看到,Step类也是一个规划实体.其中的一个成员nextTask, 它的类型是Task,它表示在链中指向后面的Entity. 大家可以想一下,为什么它可以是一个Task, 而无需是一个Step。
通过上述设计,已经实现了Chained Through Time的基本模式,可能大家还会问,上面我们实现了VariableListener, 引擎是如何触发它的呢。这就需要用到另外一种Shadow Variable了,这种Shadow Varible是用于实现在运算过程中执行额外处理的,因此称为Custom Shadow Variable.
// 自定义Shadow Variable, 它表示当 genuine被引擎改变时,需要处理哪个变量。 @CustomShadowVariable(variableListenerClass = StartTimeUpdatingVariableListener.class, sources = {@PlanningVariableReference(variableName = "previousStep")}) private Integer startTime; // 因为时间在规划过程中以相对值进行运算,因此以整数表示。
上面的代码通过@CustomShadowVariable注解,说明了Task的成员startTime是一个自定义的Shadow Variable. 同时在注解中添加了variableListenerClass属性,其值指定为刚才我们定义的,实现了VariableListener接口的类 - StartTimeUpdatingVariableListener,同时,能冠军sources属性指定,当前Custom Shadow Variable是跟随着genuine variable - previousStep的变化而变化的。
至此,关于Chained Through Time中的关键要点已全部设计实现,具体的使用可以参照示例包中有用到此模式的代码。
总结
关于时间的规划,在实际的系统开发时,并不只本文描述的那么简单,关于最为复杂的Chained Through Time模式,大家可以通过本文了解其概念、结构和要点,再结合示例包中的代码进来理解,才能掌握其要领。且现实项目中也有许许多多的个性规则和要求,需要通过大家的技巧来实现;但万变不离其宗,所有处理特殊情况的技巧,都需要甚至Optaplanner这些既有特性。因此,大家可以先通过示例包中的代码将这些特性掌握,再进行更复杂情况下的设计开如。未来若时间允许,我将分享我在项目中遇到的一些特殊,甚至是苛刻的规则要求,及其处理办法。
如需了解更多关于Optaplanner的应用,请发电邮致:kentbill@gmail.com
或到讨论组发表你的意见:https://groups.google.com/forum/#!forum/optaplanner-cn
若有需要可添加本人微信(13631823503)或QQ(12977379)实时沟通,但因本人日常工作繁忙,通过微信,QQ等工具可能无法深入沟通,较复杂的问题,建议以邮件或讨论组方式提出。(讨论组属于google邮件列表,国内网络可能较难访问,需自行解决)