关于字符编码的那些事
前言
作为程序员,在工作或者学习的过程中肯定遇到字符乱码的现象。可能是在某个文件的文本内容中出现,又或者是在网络传输的过程中遇见。而发生这些问题的原因都和今天要说主角字符编码有关系。
什么是字符编码
由于计算机本身不能表述具体的信息,因此通过规定好的数字对现实生活中的信息比如英文、中文进行描述,通过这种方式就可以表述具体的信息。而这种描述信息的方式就叫做字符编码。
ASCII(原始)
ASCII 由电报码发展而来,是第一套现代计算机用于信息交换的标准代码,它定义了128个字符。比如97代表的是'a'字符,具体定义的内容可看如下图片。而ASCII使用也比较简单,对于指定的字符只要通过表查询到对应的字节表示,然后以二进制的方式存进存储设施中即可。
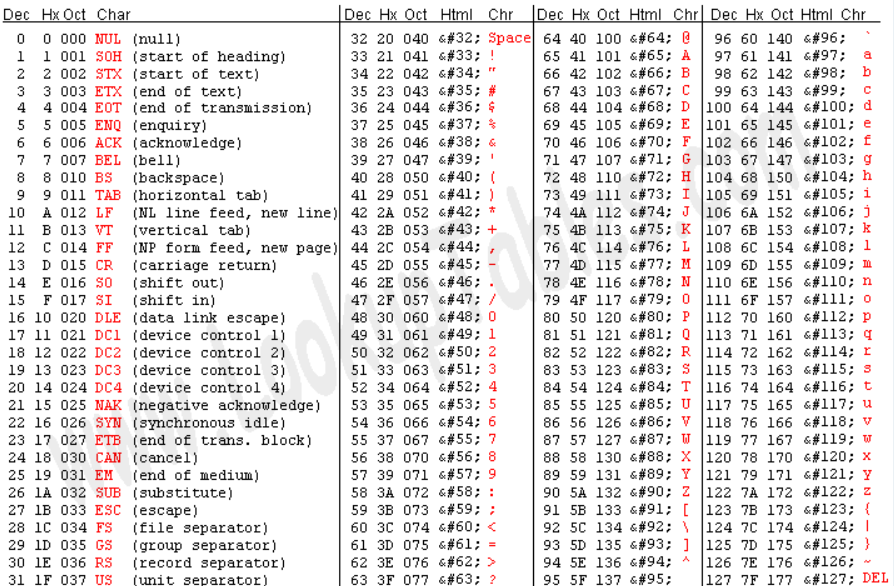
缺点:由于当时的时代原因,默认使用的8个字节来进行字节的编码。这样导致的结果是128个字符只能描述很有限的信息。
OEM字符集
上述说道字符集表示不够用的问题,各个厂商针对这个问题想到了临时兼容的方式。由于128个字符只占用了7个字节就表示完了,因此第一位字节还有128个数字的空间可以表示。比如IBM PC charset通过后面128定义一些特殊的字符。
缺点: 这种方式只是缓解了字符表示数量不够的问题,但是还是不能从根本上解决这个问题。并且由于各个厂商对于后面128位的数字定义的规则不尽相同,因此还会出现兼容性问题,同一份文档可能在不同的机器上会有不同的显示效果。
多字节字符集
对于欧美国家来说,单字节可能已经足够表示所有的字符。但是对于很多亚洲国家来说(比如中国)字符可能是数以万计的。因此单字节并不能满足需求。中国就此制定了像GB2312(记录了所有的简体字)、GBK(GB2312的扩展加上了繁体字以及一些特殊字符)的双字节字符集。
这种字符集的使用方式会涉及到多张字符集表,比如GBK,会通过第一个字节来判断具体查询哪张码表,比如0x81这个数字,由于首位字节是1,那就需要查看另一张专门记录中文字符集的表,找到对应的字符,如果首位字节是0那么和ASCII表表述一致。通过这种方式可以记录的字符数量则大大增加了。
Unicode
虽然多字节字符集解决了各自语言编码的问题,但是针对世界上所有的语言却没有一个统一的字符集来描述。因此在1991年10月Unicode组织发布了第一版Unicode字符集。该字符集涵盖了当前世界上所有的字符。
需要注意的是,Unicode还有一个比较大的变化就是将字符和字节流编码进行了解耦,在此之前比如ASCII字符集,通过查询表可以直接获取到对应的而二进制流编码(如下图),这种方式的问题在于如果新加入了不同编码方式的字符集,然后二进制流的编码方式已经固定不能更换,因此Unicode这种方式极大的提高了扩展性。比如UTF-8和UT-16两种不同的编码方式针对同一字符会有不同的结果。
具体的Unicode编码
- UTF-16/UCS-2:UTF-16通过2个或者4个子节的方式对unicode进行编码,UCS-2只支持两个字节的方式
- UTF-8(用的最多的编码方式):是一种动态的编码方式,支持1-4个字节进行编码。如果只需要一个字节则和ASCII编码方式相同,如果2-4个字节,则通过第一个字节的最高位来标记需要几个字节(比如需要两个字符则标记11并且第三位需要标记为0,另外其余两个字节的最高两位都要标记为10,剩余的位数用来填充二进制码最后编译为16进制数即可(从后向前,多出的补0))
- GB18030:这是中国的一种可以查询所有Unicode字符集的编码表,但是只能通过查表的方式进行
需要注意的是我们常说的用什么编码方式进行编码,通常可以指GBK,UTF-8,ASCII等。但是不能说Unicode因为它只是定义了字符的二进制码,但是具体的编码方式并没有定义。
总结
文章开头所说的乱码现在应该可以很好理解,通常是因为没有指定字符编码或者使用了错误的字符编码来解析导致出现乱码的情况。所以平常的开发过程中需要时刻注意文本使用的编码方式是什么,或者在响应网站输出流的时候有没有指定到具体的编码方式。
最后做个总结,本文主要通过字符编码的发展历程讲了不同的字符编码方式,从最简单的ASCII编码,扩展的OEM字符集,再到不同国家指定的字符编码(比如中国的GBK编码方式),最后发展出Unicode编码集,并且有了UTF-8、UTF-16等具体的编码方式,希望大家看了这篇文章对字符编码有一个更加深刻的理解。
转载请标明出处